Polymorphe Datenbankoperationen

Basierend auf den betriebswirtschaftlichen Vorüberlegungen sieht das architektonische Gesamtbild der Kundenakte eine Unterscheidung zwischen originären Einträgen der Kundenakte, welche in einem Verbund von Archivtabellen abgelegt werden können, und Dokumenten, welche mittels des Business Document Service ausgelagert werden können, vor. Bei beiden handelt es sich um Einträge der Kundenakte, welche von der Indexdatenbank erfasst werden müssen. Hinzu kommen Sequenzen, die ebenfalls in der Indexdatenbank enthalten sein müssen, da sie, um geschachtelt werden zu können, ebenfalls als Einträge behandelt werden müssen.
Obwohl sich all diese Eintragsarten in wesentlichen Punkten voneinander abheben, besitzen sie als indizierte Einträge der Kundenakte zahlreiche Gemeinsamkeiten, unter denen sie gebündelt betrachtet werden können. Zum Beispiel besitzen sie alle eine Reihe von Verwaltungsdaten wie den Zeitpunkt der Erzeugung, das Kürzel der auslösenden Softwarekomponente oder die Metamerkmale aus der Indexdatenbank. In einem objektorientierten Modell, das die Trennung der Verantwortlichkeiten akzentuiert, werden derartige Sachverhalte durch Erbschaftsbeziehungen ausgedrückt. Das heißt, es wird eine Oberklasse aller Einträge gebildet, unter welcher die gemeinsamen Attribute und Methoden aller Einträge zusammengefasst werden können. Von dieser wird je Eintragsart eine Klasse abgeleitet, welche die allgemeine Beschreibung eintragsspezifisch komplettiert. Dabei sollte die Mutterklasse, da es keine generischen Einträge geben kann, als abstrakte Klasse definiert werden, von der selbst keine Objektinstanzen erzeugt werden können.
Die Instanzen der Klassen repräsentieren die Einträge der Kundenakte zur Laufzeit eines sie verwendenden Programms. Zu jeder Klasse sollte es darum mindestens eine Tabelle auf der Datenbank geben, welche je persistenter Klasseninstanz einen Eintrag beinhaltet. Dies trifft auch auf die Mutterklasse zu, obwohl von dieser keine eigenständigen Instanzen erzeugt werden sollten. Der Grund hierfür ist zum einen, dass jede Objektinstanz der Subklassen indirekt auch eine Instanz der Mutterklasse ist. Zum anderen muss für jeden Eintrag die Möglichkeit der Indizierung bestehen, so dass diese Funktionalität von der Mutterklasse erbracht werden kann. Sie stellt somit die Verbindung von den Bestandsdatenbanken zur Indexdatenbank her. Allerdings muss die direkte Entsprechung eines Tabelleneintrages mit einer Klasseninstanz an dieser Stelle aufgelockert werden. Denn durch die Mutterklasse sollen natürlich alle Metamerkmale eines Eintrages verwaltet werden, nicht nur ein einziger.
Sowohl bei der Objekterzeugung als auch bei der Ablage von Objektdaten auf der Datenbank muss sichergestellt sein, dass jede Klasse, von der eine Objektinstanz abhängig ist, die Möglichkeit erhält, auf die Datenbank zuzugreifen. Denn andernfalls kann die Vollständigkeit der persistierten Daten nicht gewährleistet werden. Zu einem gewissen Grade steht dies im Gegensatz zur objektorientierten Generalisierung, aufgrund derer die Methoden zum Datenbankzugriff bereits in der obersten Mutterklasse angesiedelt werden müssen, so dass sie von den abhängigen Unterklassen bei jeweils gleicher Aufrufsignatur domänenspezifisch implementiert werden können1. Da aber die Subklassen nicht nur bezüglich ihrer Funktionalitäten sondern auch bezüglich ihrer Dateninhalte auf ihrer Superklasse aufbauen, darf, um die Trennung der Verantwortlichkeiten nicht zu gefährden, die in der Superklasse enthaltene Implementierung der Datenbankmethoden trotz Überdefinition nicht verloren gehen.
Vom ABAP-Laufzeitsystem wird dies insofern berücksichtigt, als dass jedes Objekt ein automatisches Attribut namens super besitzt, welches eine Referenz auf den geerbten Teil des Objekts darstellt. Sein Typ entspricht deshalb immer der Superklasse des Objekts und alle damit durchgeführten Aufrufe beziehen sich stets auf die Implementierung der Superklasse, unabhängig davon, ob eine polymorphe Überdefinition vorliegt. (Vgl. [WOLF07] S. 36/58).
Mit Blick auf die Datenbankmethoden ergibt sich also, dass jede Methode, bevor sie ihre eigenen Operationen durchführt, via super ihre namensgleiche Umsetzung der Mutterklasse ausführen muss. Denn auf diese Weise wird gewährleistet, dass auf die Datenbank in umgekehrter Aufrufreihenfolge stets von der allgemeinen zur speziellen Klasse hin zugegriffen wird, ohne dass eine Ebene der Vererbungshierarchie übersprungen wird. Ebenso wird sichergestellt, das die zwischen den korrelierenden Tabellen bestehenden Fremdschlüsselbeziehungen, welche notwendig sind, um die Vererbungsmimik auf das relationale Datenbankschema zu übertragen, nicht verletzt werden, da davon ausgegangen werden kann, dass sich diese analog zum objektorientierten Modell von der speziellen zur allgemeinen Tabelle hin orientieren.
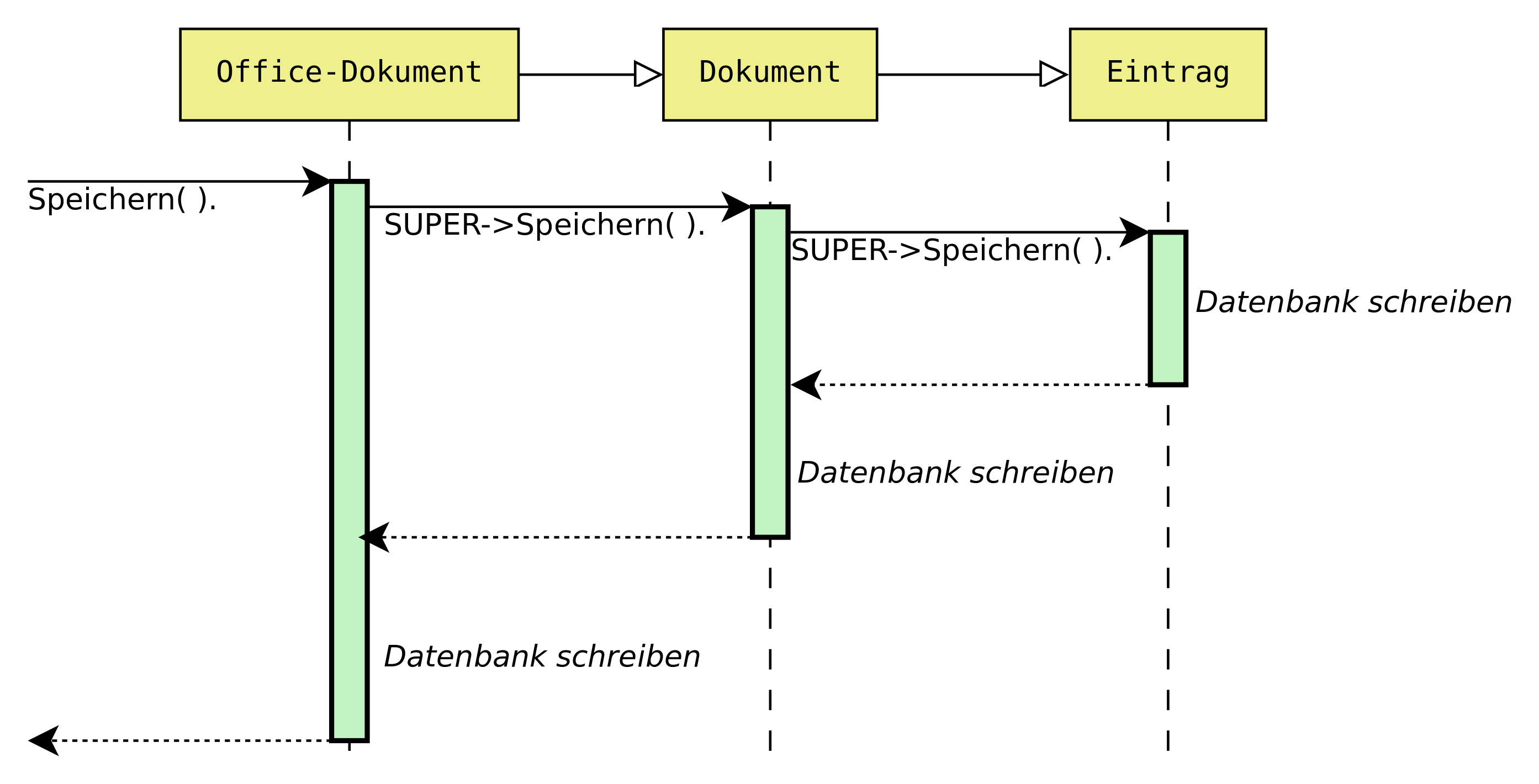
Abbildung 1: Polymorphe Datenbankoperationen
Quelle: Eigene Darstellung
Die obige Abbildung visualisiert das Verfahren für den Fall dreier Hierarchieebenen, weshalb im oberen Teil der Graphik die Klassennamen mitsamt ihren Erbschaftsbeziehungen eingezeichnet sind. Der untere Teil zeigt den zeitlichen Verlauf aller Methodenaufrufe und Datenbankzugriffe, der sich aus dem externen Aufruf der Speichern-Methode eines Objekts ergibt. Entsprechend des beschriebenen Mechanismus ruft jede Methode erst die Implementierung der eigenen Oberklasse auf, bevor sie selbst auf die Datenbank zugreift, was dazu führt, dass von der allgemeinen Eintragsklasse aus beginnend, die Datenbank in umgekehrter Reihenfolge beschrieben wird.
Ein objektorientiertes Datenmodell, das regen Gebrauch von Vererbungsmechanismen macht, bietet der Kundenakte zwar die nötige Flexibilität, um verschiedene Eintragsarten unter einem ganzheitlichen Konzept zu verwalten, es impliziert aber auch, dass für die Ablage der Eintragsdaten mehrere Tabellen zum Einsatz kommen, deren Datensätze nur in Kombination einen vollständigen Eintrag ausmachen. Glücklicherweise stellt das zuvor beschriebene, polymorphe Zugriffsverfahren sicher, dass für alle Datenbankoperationen die richtigen Tabellen angesprochen werden, doch ein Gesichtspunkt wird dabei außer Acht gelassen. Nämlich die Frage, anhand welchen Kriteriums beim Auslesen eines bestehenden Akteneintrags determiniert werden kann, welche Klasse letztlich instantiiert werden muss, um den Eintrag zu repräsentieren. Denn nur wenn die zu einem Eintrag adäquate Klasse eingesetzt wird, kann die polymorphe Abbildung zwischen dem relationalen Datenbankschema und seiner objektorientierten Verschalung fehlerfrei funktionieren.
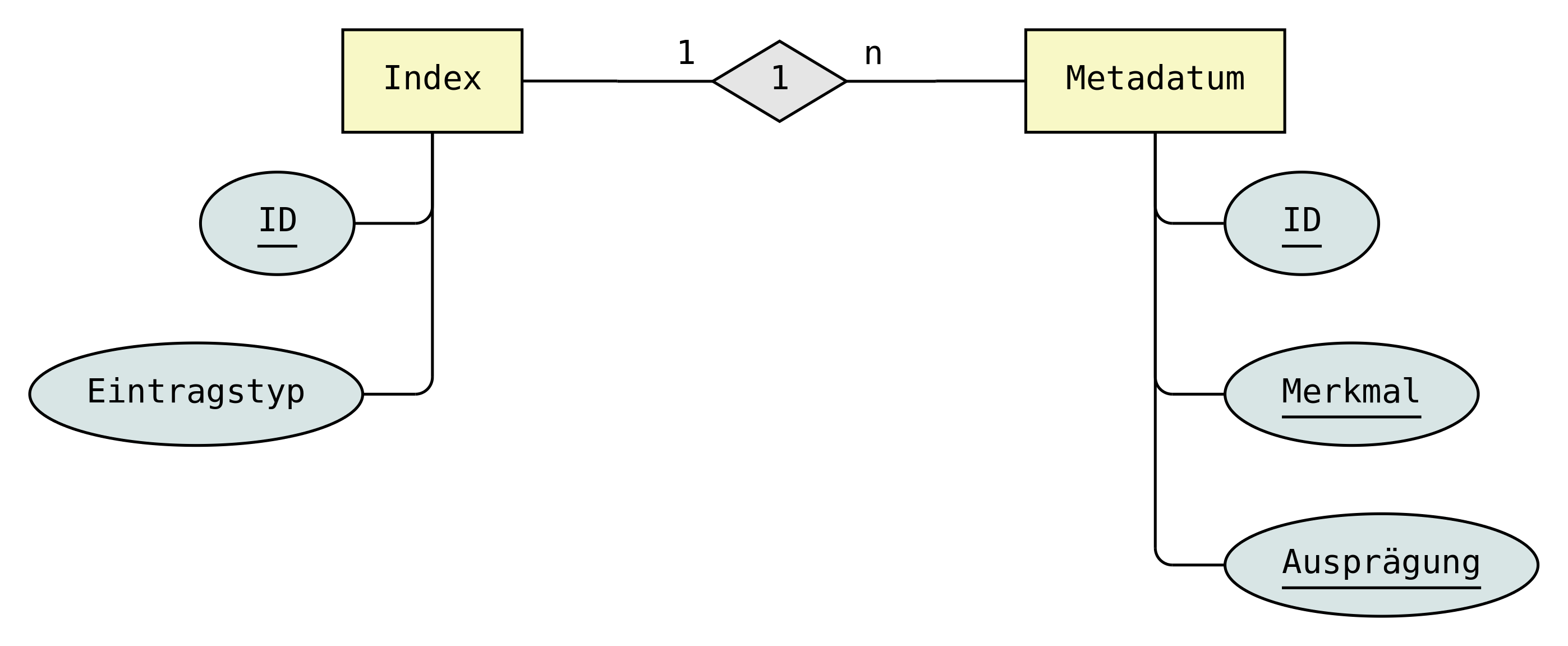
Naturgemäß kann diese Aufgabe nicht von den repräsentierenden Klassen während ihrer Instanzerzeugung beantwortet werden, da zu diesem Zeitpunkt die Auswahl der verwendeten Klasse bereits getroffen wurde. Die Entscheidung muss also ausgelagert werden, in dem Sinne dass eine speziell für die Objekterzeugung zuständige Einheit - ein sogenannter Erbauer2 - verwendet wird, welcher als Blackbox funktioniert und immer das richtige Objekt generiert. Somit wird dafür Sorge getragen, dass die Entscheidung über das zu erzeugende Objekt nur von einer zentralen Implementierung getroffen wird, doch das Entscheidungsproblem wird dadurch noch nicht gelöst. Endgültige Klarheit kann darum nur die Datenbank selbst schaffen, indem sie eine Indextabelle vorhält, welche einerseits verwendet wird, um jeden Eintrag mit einer eindeutigen Kennnummer zu versehen und welche andererseits den Typus eines jeden Eintrags speichert.
Abbildung 2: ER-Diagramm der Indextabellen
Doch an dieser Stelle endet die Indizierung nicht, denn eine weitere Facette ihrer stellt die Suche nach den abgelegten Einträgen anhand übergreifender Kriterien dar, welche unabhängig von der Eintragsart auf alle Akteneinträge zutreffen können. Insbesondere handelt es sich hierbei um Kriterien, welche über den reinen Informationsgehalt der Einträge hinausgehen, diesem aber erst seine betriebswirtschaftliche Bedeutung verleihen, wie zum Beispiel die Verknüpfung zu einem Geschäftspartner oder zu einer zusammenhängenden Kette von Ereignissen. Derartige Informationen können auf vielfältige Weise in der Datenbank abgelegt werden, zum Beispiel in Form von dedizierten Verknüpfungstabellen mit ausgeprägten Fremdschlüsselbeziehungen. Allerdings müssen dabei die Anforderungen einer zentralen Suchfunktion berücksichtigt werden. Denn diese muss in erster Linie unkompliziert und performant sein, sie muss aber auch flexibel genug sein, um die Formulierung aussagekräftiger Suchanfragen zu gestatten, welche in der Lage sind, bereits die ersten Treffermengen hinreichend präzise einschränken.
Aus diesem Grund wird anstelle der Verwendung von heterogenen Verknüpfungstabellen angeregt, mithilfe von Metamerkmalen eine Art Schlagwortverzeichnis aufzubauen, das die Möglichkeit bietet, zu jedem Akteneintrag mehrere Metamerkmale zu hinterlegen, die durch eine Wertausprägung näher spezifiziert werden können. Ihre Ablage kann in einer singulären Tabelle erfolgen, welche je Eintrag in der Kundenakte und je zutreffendem Metamerkmal einen Datensatz vorsieht. Somit gestaltet sich die Abfrage flexibel genug, um verschiedene Aspekte in eine Suchanfrage einfließen zu lassen, es entsteht aber auch kein Laufzeitengpass, da zur Bildung der Trefferliste keine Mengenoperationen benötigt werden, um verschiedene Teilmengen aus unterschiedlichen Tabellen zu harmonisieren. (...)
1 Dieses Vorgehen wird Überdefinition genannt und hat die Polymorphie der geerbten Methoden zur Folge. Sowohl nach Aussage von [BÖHM93] (S. 395-396) als auch von [WOLF07] (S. 36/58) stellt es eines der Kernkonzepte der Objektorientierung dar, um die Wiederverwendbarkeit von Quellcode zu erhöhen.
2 Vgl. die Beschreibung des Erbauer-Patterns aus [GAMM04] (S. 119-123)
BÖHM93: Rolf Böhm et al. (1993), System-Entwicklung in der Wirtschafts-Informatik, 2. überarbeitete und erweiterte Auflage, Verlag der Fachvereine an den schweizerischen Hochschulen und Techniken AG, Zürich
GAMM04: Erich Gamma et al. (2004), Entwurfsmuster: Elemente wiederverwendbarer objektorientierter Software, 1. Auflage, Addison-Wesley Verlag, München
WOLF07: Frank Wolf (2007), ABAP Objects, 1. Auflage, dpunkt.verlag GmbH, Heidelberg